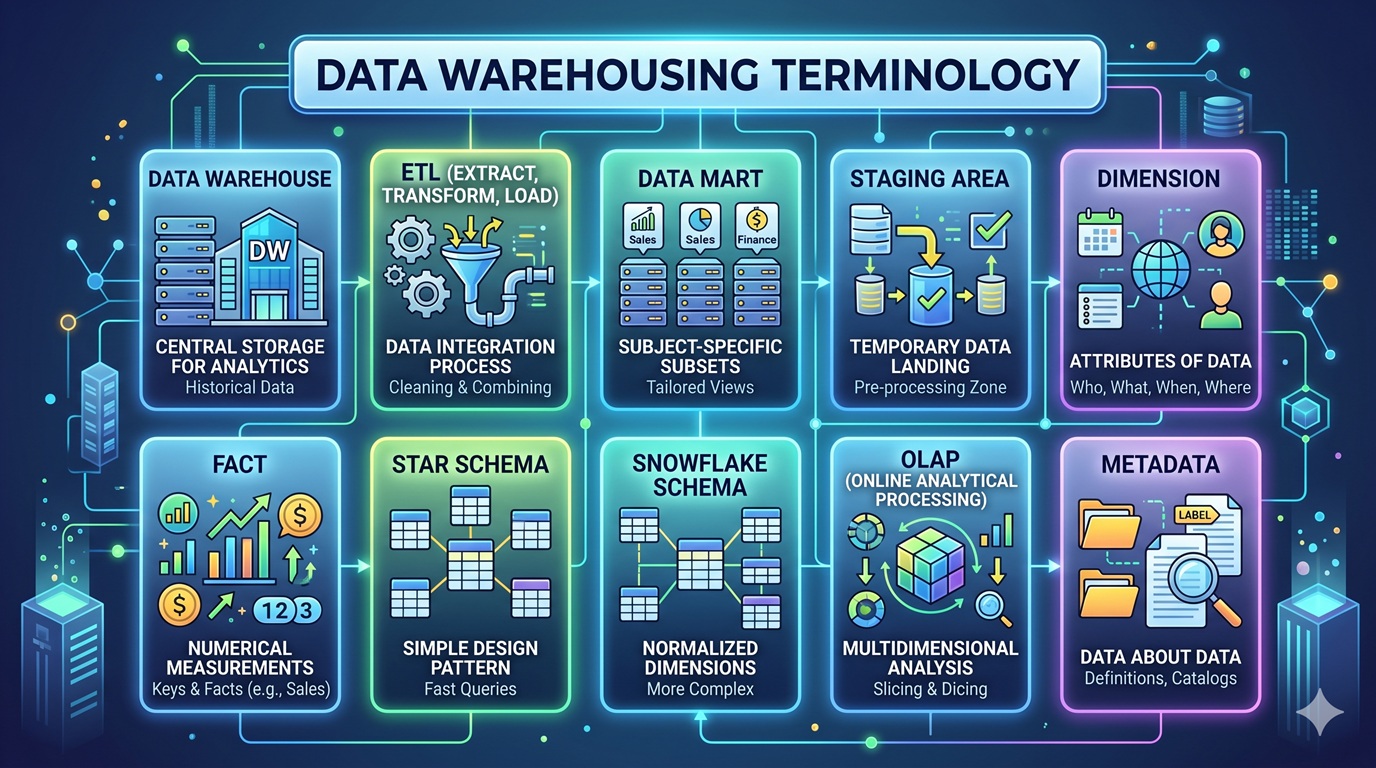
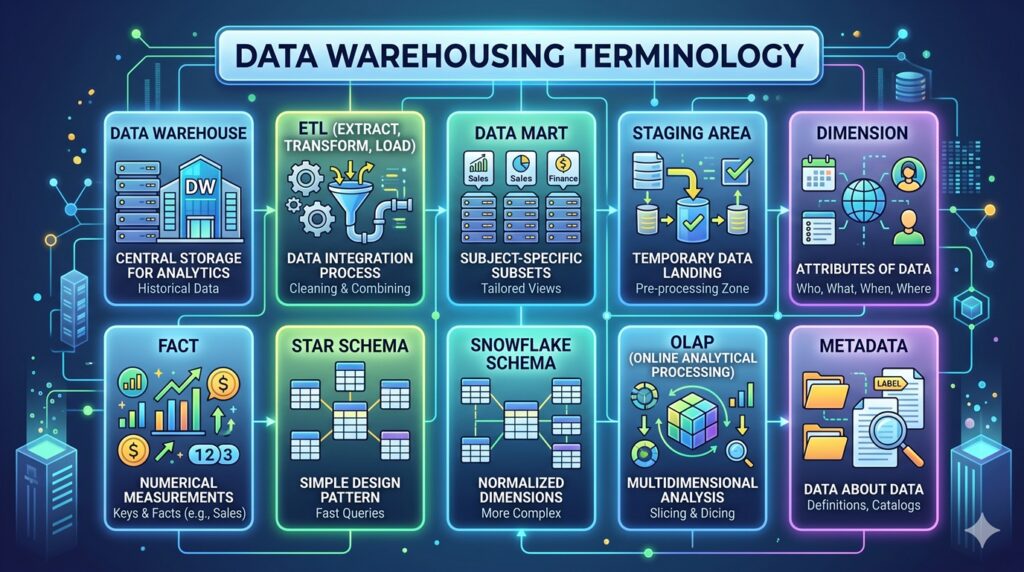
Here is a comprehensive list of essential data warehousing terminology, categorized by their function within the data warehousing lifecycle.
Core Concepts & Architecture
- Data Warehouse (DW): A centralized repository that stores current and historical data from multiple operational systems. It is optimized for reporting, analytics, and business intelligence rather than transaction processing.
- Enterprise Data Warehouse (EDW): A large-scale data warehouse that encompasses data from across an entire organization, serving as the “single source of truth.”
- Data Mart: A specialized, smaller subset of a data warehouse focused on a specific business line, department, or subject area (e.g., Sales Data Mart or HR Data Mart).
- Data Lake: A storage repository that holds a vast amount of raw data in its native format (structured, semi-structured, and unstructured) until it is needed for analytics.
- Operational Data Store (ODS): A database designed to integrate data from multiple sources for operational reporting and real-time analysis before it is moved to the data warehouse.
- Staging Area: A temporary storage zone where raw data is extracted from source systems, held, and transformed before being loaded into the data warehouse.
Data Processing & Integration
- ETL (Extract, Transform, Load): The traditional process of pulling data from source systems (Extract), converting it into a consistent format and cleaning it (Transform), and writing it into the data warehouse (Load).
- ELT (Extract, Load, Transform): A modern variation where data is extracted and immediately loaded into the data warehouse (often cloud-based), leveraging the warehouse’s processing power to perform transformations later.
- Data Cleansing (Data Scrubbing): The process of detecting and correcting (or removing) corrupt, inaccurate, or incomplete records from a dataset.
- Change Data Capture (CDC): A software design pattern used to determine and track data that has changed in the source systems so that only the altered data (deltas) is extracted and loaded, rather than doing a full load every time.
Data Modeling & Schema Design
- Dimensional Modeling: A data design concept optimized for data retrieval and querying, heavily used in data warehousing. It organizes data into Facts and Dimensions.
- Fact Table: The central table in a dimensional model. It contains quantitative, measurable data (the “facts” or metrics, like sales amount or quantity sold) and foreign keys that link to dimension tables.
- Dimension Table: Tables that surround the fact table and contain descriptive attributes (the “context”, such as time, location, product, or customer details) used to filter, group, and label the facts.
- Star Schema: The simplest dimensional model design where a central fact table is directly connected to multiple unnormalized dimension tables, resembling a star.
- Snowflake Schema: A more complex variation of the star schema where the dimension tables are normalized (split into additional tables) to reduce data redundancy, resembling a snowflake.
- Granularity (Grain): The level of detail stored in a fact table. A “fine grain” means highly detailed data (e.g., individual items on a single receipt), while “coarse grain” means summarized data (e.g., total daily sales by store).
Keys & Attributes
- Primary Key: A unique identifier for a specific record in a table.
- Foreign Key: A field in one table that uniquely identifies a row of another table, used to establish and enforce a link between the data in the two tables.
- Surrogate Key: An artificially generated, sequential integer used as a primary key in a data warehouse dimension table, independent of the operational system’s original “natural” key.
- Natural Key (Business Key): The original unique identifier from the source operational system (e.g., an Employee ID or Social Security Number).
- Slowly Changing Dimension (SCD): A dimension whose data changes over time, rather than changing on a regular schedule. There are several methods for handling these:
- Type 1: Overwrite the old data with new data (no history kept).
- Type 2: Add a new row with the updated data and a new effective date (full history kept).
- Type 3: Add a new column to track the previous value (limited history kept).
Analysis & Access
- OLTP (Online Transaction Processing): Systems optimized for fast, reliable transaction handling and routine data entry (e.g., ATM networks, e-commerce checkout). These act as the source systems for a data warehouse.
- OLAP (Online Analytical Processing): Systems optimized for querying and reporting, allowing users to analyze multidimensional data interactively from multiple perspectives.
- Data Cube: A multidimensional array of data used in OLAP, allowing data to be modeled and viewed in multiple dimensions simultaneously.
- Roll-up / Drill-down: Analytical operations. “Rolling up” summarizes data (e.g., viewing sales by year instead of month), while “drilling down” exposes more detail (e.g., viewing sales by city instead of state).
- Slice and Dice: The ability to look at information from different perspectives by filtering out specific “slices” of a data cube.
- Business Intelligence (BI): The strategies and technologies used by enterprises for the data analysis of business information, typically utilizing the data warehouse as its backend.
Governance & Management
- Metadata: “Data about data.” In a data warehouse, it defines the source, type, format, structure, and meaning of the data, helping users understand what exists in the warehouse.
- Data Lineage: The lifecycle of data—tracking where it originated, how it was transformed, and where it moves over time.
- Master Data Management (MDM): A method used to define and manage the critical data of an organization to provide a single point of reference.
- Data Governance: The overall management of the availability, usability, integrity, and security of the data employed in an enterprise.
Advanced Data Modeling & Schema Design
- Data Vault: A hybrid data modeling approach (combining elements of 3NF and dimensional modeling) designed for long-term historical storage of data from multiple systems. It focuses on agility, auditability, and scalability.
- Conformed Dimension: A dimension that has the exact same meaning and content when referred to from different fact tables or data marts (e.g., a standardized “Date” or “Customer” dimension used across the entire enterprise).
- Degenerate Dimension: A dimension key in a fact table that does not have its own corresponding dimension table because all interesting attributes have already been placed in other dimensions (e.g., a transaction number, invoice number, or order number).
- Junk Dimension: A single dimension table that combines several low-cardinality flags and indicators (like Yes/No, True/False statuses) to avoid cluttering the fact table with too many foreign keys or creating too many tiny dimension tables.
- Role-Playing Dimension: A single physical dimension table that is referenced multiple times in a fact table for different purposes (e.g., a single “Date” table serving simultaneously as “Order Date,” “Shipping Date,” and “Delivery Date”).
- Factless Fact Table: A fact table that contains no measurable facts (metrics) but is used to record events or map many-to-many relationships between dimensions (e.g., tracking student attendance or recording that an employee was assigned to a project).
- Late-Arriving Dimension: A scenario where a fact record arrives at the data warehouse before its corresponding dimension record is available. Dummy dimension records are temporarily created to maintain referential integrity.
Modern Architecture & Storage
- Cloud Data Warehouse: Data warehouses provided as a managed service in the cloud (e.g., Google BigQuery, Amazon Redshift, Snowflake). They offer immense scalability, elasticity, and often decouple storage and computing power.
- Columnar Database: A database management system that stores data by columns rather than by rows. This is highly optimized for data warehouses because it drastically speeds up analytical queries (like aggregations) and allows for high data compression.
- Materialized View: A database object that contains the results of a query. Unlike a standard view, which runs the underlying query every time it is accessed, a materialized view physically stores the computed data, significantly speeding up complex reporting.
- Data Fabric: An architecture that provides a unified, integrated, and intelligent data management environment across diverse endpoints (on-premises, cloud, edge) using automated data integration.
- Data Mesh: A decentralized socio-technical approach to managing data at scale. Instead of a central data warehouse team, data is treated as a product, and ownership is distributed to domain-specific business teams.
Data Loading & Performance Optimization
- Upsert (Merge): A standard database operation that attempts to insert new rows into a table; if the row already exists (based on a primary key), it updates the existing row instead.
- Partitioning: The process of dividing a very large table or index into smaller, more manageable pieces (partitions) based on a specific key (like date ranges or geographic regions) to improve query performance and data maintenance.
- Bitmap Index: A highly compressed database index that uses bitmaps (arrays of bits). It is exceptionally efficient in data warehousing environments for querying columns with low cardinality (few unique values, like gender or payment status).
- Pushdown Optimization: An ELT technique where the data integration tool translates the transformation logic into SQL and “pushes it down” to the target database to process, utilizing the data warehouse’s superior computing power rather than the ETL server’s.
Analytics & Processing Types
- Ad-hoc Query: A non-standard, custom query created by an end-user to answer a specific, usually one-off, business question that is not covered by standard, pre-built reports.
- MOLAP (Multidimensional OLAP): Analytical processing where data is physically stored in an optimized, pre-calculated multidimensional data cube.
- ROLAP (Relational OLAP): Analytical processing where data remains in the relational database, and complex SQL queries are generated on the fly to simulate a multidimensional view.
- HOLAP (Hybrid OLAP): A combination of the above, typically keeping summarized, high-level data in a fast MOLAP cube and detailed data in standard ROLAP tables.
Modern Data Paradigms & Storage Formats
- Data Lakehouse: A modern architecture that seeks to combine the best features of both data lakes and data warehouses. It provides the flexibility and low-cost storage of a data lake with the structured querying, reliability, and ACID transactions of a data warehouse.
- ACID Transactions: A set of properties (Atomicity, Consistency, Isolation, Durability) that guarantee database transactions are processed reliably. Historically missing from data lakes, but now a key feature of Data Lakehouses.
- Delta Lake / Apache Iceberg / Apache Hudi: Open-source table formats that sit on top of data lakes, bringing ACID transactions, scalable metadata handling, and time travel (data versioning) to raw storage.
- Parquet / ORC (Optimized Row Columnar): Open-source, highly efficient columnar file formats. They are standard storage formats for big data environments because they compress well and allow analytical queries to read only the necessary columns.
- Zero-Copy Cloning: A feature in some cloud data warehouses (like Snowflake) that allows users to create a complete, fully usable clone of a database, schema, or table in seconds without duplicating the underlying physical data storage, saving costs.
Data Engineering & Pipelines
- Data Pipeline: The broader, automated set of processes that extract data from various sources, transform it, and route it to its destination. ETL/ELT are specific processes within a pipeline.
- Data Orchestration: The automated configuration, coordination, and management of complex data pipelines. It ensures that various scripts, tools, and queries run in the correct sequence and handles failures.
- DAG (Directed Acyclic Graph): A visual and mathematical representation used in orchestration tools (like Apache Airflow). It maps out the sequence of tasks in a data pipeline, ensuring operations run in the correct order based on dependencies, without looping back on themselves.
- Reverse ETL: The relatively new practice of syncing transformed, enriched data out of the data warehouse and pushing it back into operational systems (like Salesforce, HubSpot, or Zendesk) to trigger workflows or inform frontline workers.
- Streaming Data (Real-Time Processing): Continuous ingestion and processing of data as it is generated (e.g., website clicks, IoT sensor data), as opposed to “batch processing” where data is loaded in scheduled chunks.
Advanced Fact Table Types & History Tracking
- Transactional Fact Table: The most basic fact table. It records a discrete event at a single point in time (e.g., one row per item on a store receipt). Once loaded, these rows are rarely updated.
- Periodic Snapshot Fact Table: Records summarized data at predefined regular intervals. For example, logging a bank account balance or total warehouse inventory at exactly midnight every day.
- Accumulating Snapshot Fact Table: Used to track the complete lifecycle of a process with defined milestones. A single row is created when the process starts, and that same row is updated as the process progresses (e.g., an order moving from Placed to Processing to Shipped to Delivered, with timestamps for each step).
- SCD Type 4 (History Table): A method for handling slowly changing dimensions where current data is kept in the main dimension table, and all historical changes are moved to a separate “history” table.
- SCD Type 6 (Hybrid): A complex method that combines elements of Type 1, 2, and 3 to track historical changes, current states, and previous states within the same row.
Advanced Governance, Quality & Security
- Data Catalog: An organized, heavily searchable inventory of all data assets in an organization. It functions like a search engine for enterprise data, allowing analysts to easily find the tables or metrics they need.
- Data Dictionary: A centralized repository of detailed information about specific data fields, including business definitions, data types, origin, acceptable values, and relationships to other data.
- Data Observability: A concept borrowed from software engineering. It is an organization’s proactive capability to continuously monitor the health, quality, and reliability of the data pipeline (checking for sudden volume drops, schema changes, or null value spikes).
- Data Contract: A formal agreement between the software engineers generating data (the source) and the data engineers consuming it. It guarantees that the schema and quality of the source data will not change without warning, preventing broken pipelines.
- Row-Level Security (RLS): A security protocol that restricts database access based on the user’s role. For example, a regional manager querying the main sales table will automatically only see rows pertaining to their specific region.
- Column-Level Security / Data Masking: Protocols that restrict access to or obfuscate specific columns within a table. For instance, allowing an analyst to see customer purchasing behavior but automatically masking or hiding the column containing Social Security Numbers or Credit Card details.
Foundational Methodologies
- Kimball Methodology (Bottom-Up): A popular data warehousing architecture conceptualized by Ralph Kimball. It focuses on building business-process-specific Data Marts first using dimensional modeling (star schemas), which are then tied together using conformed dimensions to create the overarching enterprise data warehouse.
- Inmon Methodology (Top-Down): A data warehousing architecture conceptualized by Bill Inmon (often called the “father of the data warehouse”). It advocates for building a highly normalized (3NF) centralized Enterprise Data Warehouse first, from which smaller, summarized departmental Data Marts are subsequently extracted.
- CIF (Corporate Information Factory): The formal architectural framework proposed by Bill Inmon that encompasses the operational systems, the ODS, the EDW, and the dependent data marts.
- 3NF (Third Normal Form): A database schema design standard used primarily in OLTP systems and Inmon-style data warehouses. It focuses on reducing data duplication and ensuring data integrity by splitting data into many related tables.
Hardware Architecture & Processing
- MPP (Massively Parallel Processing): A hardware and software architecture where hundreds or thousands of separate processors (or compute nodes), each with its own memory and operating system, work in parallel to execute a single, massive analytical query. Most modern cloud data warehouses use MPP.
- SMP (Symmetric Multiprocessing): An architecture where multiple processors share a single operating system and memory pool. This is typically used for smaller-scale databases or traditional OLTP systems rather than large data warehouses.
- Data Warehouse Appliance: A specialized, pre-configured combination of hardware (servers, storage, network) and software (DBMS) designed explicitly for data warehousing out of the box (e.g., legacy systems like Teradata or Netezza).
- Data Skew: A performance bottleneck in MPP systems that occurs when data is distributed unevenly across the compute nodes. One node ends up doing the majority of the work while others sit idle, slowing down the entire query.
The Semantic Layer & BI Engineering
- Semantic Layer: A logical translation layer that sits between the complex, technical tables of the data warehouse and the end-user BI tools. It translates raw database column names (like
CUST_ID_001) into business-friendly terms (like “Customer Account Number”). - Metrics Layer (Metrics Store / Headless BI): A modern evolution of the semantic layer where key business calculations (like “Active Daily Users” or “Gross Margin”) are defined centrally in code just once. Any BI tool (Tableau, Looker, Excel) that connects to the metrics layer will display the exact same numbers, preventing discrepancies across departments.
- Data Virtualization: A logical data layer that allows applications to retrieve and manipulate data without requiring technical details about the data, such as how it is formatted or where it is physically located. It creates a “virtual” data warehouse without actually moving or copying the data.
Loading Patterns & Data Profiling
- Schema-on-Write: The traditional data warehouse approach where the table structure (schema) must be strictly defined before any data can be loaded into it.
- Schema-on-Read: The data lake approach where data is loaded in its raw, unstructured format. The structure or schema is only applied dynamically at the moment the analyst writes a query to read the data.
- Micro-batching: A data loading technique that falls between batch processing and true real-time streaming. Data is collected and loaded in very small, frequent chunks (e.g., every 1-5 minutes) to provide near-real-time analytics without the infrastructure overhead of true streaming.
- Data Profiling: The crucial first step in data warehousing where engineers analyze raw source data to understand its structure, content, and quality before building the ETL pipeline. This involves checking for null counts, data type consistency, and unique values.
- Data Stewardship: The business role responsible for ensuring the ongoing quality, accuracy, and appropriate use of data within the warehouse, acting as the bridge between IT/Data Engineering and the business users.
Specialized Dimensional & Vault Modeling
- Outrigger Dimension: A dimension table that is connected to another dimension table rather than directly to the central fact table. It is used when a dimension needs to inherit attributes from another dimension (e.g., a “Customer” dimension linking to a “Demographics” outrigger).
- Hash Key: A primary key generated using a cryptographic hashing algorithm (like MD5 or SHA-256) on one or more business keys. Highly utilized in Data Vault modeling to create deterministic, fast-joining identifiers across different source systems.
- Bridge Table (Junction Table): A table created to resolve a many-to-many relationship between a fact table and a dimension table (e.g., an account with multiple account holders, or a medical patient with multiple diagnoses for a single visit).
- Closure Table (or Adjacency List): Specialized table structures used in relational data warehouses to query deep hierarchies (like a company’s organizational chart or a product bill-of-materials) without writing excessively complex, recursive SQL.
- Tombstone Record: A marker or flag placed on a record in a data warehouse indicating that the corresponding record in the source system has been deleted (a “soft delete”). This preserves the historical data while showing it is no longer active.
AI, Machine Learning, and Advanced Context
- Feature Store: A centralized data repository—often integrated with or sitting alongside the data warehouse—used specifically to organize, store, and serve curated data “features” (variables) for machine learning models.
- Vector Storage (Vector Database integration): The capability of modern data warehouses to store and query high-dimensional vectors (embeddings). This allows the warehouse to support AI-driven semantic searches, similarity matching, and Retrieval-Augmented Generation (RAG) applications directly alongside traditional relational data.
- Continuous Intelligence: A design pattern where real-time analytics are integrated directly into business operations, prescribing actions automatically in response to data as it arrives in the warehouse or streaming platform.
Cloud Operations & Economics
- Data FinOps (Financial Operations): The practice of managing, monitoring, and optimizing the operational costs of cloud data warehouses. Because cloud storage and compute (queries) are billed by usage, FinOps ensures data teams write efficient queries and drop unused tables.
- Serverless Compute: A cloud data warehouse deployment model where the organization does not provision, manage, or scale physical or virtual servers (nodes). The cloud provider dynamically allocates compute resources exactly when a query is run and spins them down immediately after.
- Hot, Warm, and Cold Storage: Data tiering strategies based on how often data is accessed.
- Hot: Highly optimized, expensive storage for data queried daily (e.g., this year’s sales).
- Warm: Cheaper storage with slightly slower retrieval for less frequent queries.
- Cold (Archive): Very cheap, slow-retrieval storage for compliance or historical data rarely accessed (e.g., sales data from 10 years ago).
- Compute Credits (or Slots): The billing mechanism used by cloud data warehouses. Organizations purchase or consume credits based on the amount of processing power and time required to execute their ETL jobs and analytical queries.
Data Testing & Integrity
- Data Reconciliation: The automated process of comparing data in the target data warehouse against the original source systems to verify that the ETL/ELT pipeline moved everything correctly without dropping or duplicating records.
- Data Anomaly Detection: Automated monitoring within the data pipeline that uses statistical models or machine learning to flag data points that deviate significantly from historical norms (e.g., an unexplained 500% spike in recorded sales for a single day).
- Unit Testing (for Data): The practice of testing individual SQL transformations or specific ETL pipeline components in an isolated environment with mock data to ensure the logic works perfectly before deploying it to the production data warehouse.
Data Quality Dimensions
When data engineers and stewards evaluate the health of data in a warehouse, they measure it against these standard dimensions:
- Completeness: The degree to which all required data is present (e.g., ensuring no “First Name” fields are blank if the system requires them).
- Accuracy: The degree to which the data correctly describes the real-world object or event (e.g., a customer’s address in the warehouse matches where they actually live).
- Consistency: The absence of difference between data items representing the same object across different tables or systems (e.g., total sales for Q1 should be the same whether pulled from the Finance Data Mart or the Sales Data Mart).
- Validity: The degree to which data conforms to defined business rules or formats (e.g., ensuring an email address contains an “@” symbol).
- Timeliness: The degree to which data represents reality from the required point in time (e.g., daily sales reports being available exactly at 8:00 AM the following day).
- Uniqueness: Ensuring that no entity exists more than once within the dataset (e.g., no duplicate customer records).
Advanced Query Optimization & Execution
- Query Plan (Execution Plan): The sequence of steps generated by the database engine to execute a SQL query most efficiently. Engineers analyze these plans to figure out why a report is running slowly.
- Predicate Pushdown: An optimization technique where the database engine filters out unwanted data (the “predicates” or
WHEREclauses) as early as possible in the execution plan, ideally right at the storage level, before the data is moved into memory. - Partition Pruning: When querying a partitioned table, the database optimizer analyzes the query and completely ignores (prunes) the partitions that do not contain relevant data, drastically speeding up the search.
- Cost-Based Optimizer (CBO): The “brain” of the database engine. It evaluates several different ways to execute a query and chooses the one that will cost the least in terms of CPU, memory, and disk I/O.
- Spill to Disk: A performance issue that occurs when a query requires more working memory (RAM) than is allocated to it. The system is forced to temporarily write the intermediate processing data to the physical hard drive, which drastically slows down the query.
Project Implementation Artifacts
- Source-to-Target (S2T) Mapping: A critical spreadsheet or document created by data analysts. It maps exactly which column from the raw source system corresponds to which column in the final data warehouse table, including the specific transformation logic required to get it there.
- Enterprise Data Bus Matrix: A strategic planning document (central to the Kimball methodology) that identifies and maps the core business processes (rows) against the conformed dimensions (columns) shared across the enterprise.
- Conceptual Data Model: The highest-level view of data, showing only the major business entities and their relationships, without technical details. Used for initial discussions with business stakeholders.
- Logical Data Model: Adds details to the conceptual model, including all required attributes (columns) and exact relationships, but remains independent of any specific database software.
- Physical Data Model: The final blueprint. It translates the logical model into the specific syntax and constraints of the chosen database technology (e.g., defining precise data types like
VARCHAR(255)orINT). - Business Glossary: A business-facing document that clearly defines business terms and metrics in plain language, whereas a Data Dictionary is more technical and focuses on database columns and types.
Historical “Big Data” Ecosystem Context
- Hadoop: An open-source framework that allowed for the distributed processing of massive datasets across clusters of commodity computers. It was the precursor to modern cloud data lakes.
- HDFS (Hadoop Distributed File System): The storage component of Hadoop, designed to hold vast amounts of unstructured data.
- MapReduce: The original, highly complex programming model used to process data stored in Hadoop. It involved writing Java code to map data into key-value pairs and then reduce it to final results.
- Hive: A data warehouse software project built on top of Hadoop. It was revolutionary because it allowed analysts to query the raw files in HDFS using a SQL-like language (HiveQL), bypassing the need to write complex MapReduce Java code.
- Data Swamp: A derogatory term for a Data Lake that has become disorganized, undocumented, and unmanageable due to a lack of data governance, making the stored data effectively useless.
Advanced Temporal & Relational Modeling
- Bitemporal Modeling: A highly complex data modeling technique that tracks two different timelines for a single record: the Valid Time (when the event actually happened in the real world) and the Transaction Time (when the event was recorded in the database). This is critical for exact historical auditing in finance and insurance.
- Anchor Modeling: An agile modeling technique suited for environments where the data structure changes constantly. It heavily normalizes data, extending it into 6NF (Sixth Normal Form), where tables are created for virtually every attribute to prevent null values and allow for rapid schema evolution without breaking existing models.
- Supertype / Subtype (Polymorphism): A modeling pattern where common attributes are stored in a generalized parent table (the Supertype, e.g.,
Party), and specific, mutually exclusive attributes are stored in child tables (the Subtypes, e.g.,Personvs.Organization). - Self-Referencing Table (Recursive Relationship): A table containing a foreign key that references its own primary key. Commonly used to represent hierarchical data like an employee-manager relationship within a single
Employeetable.
Physical Optimization & Maintenance
- Clustering Key: A property that dictates how data is physically sorted and co-located on the storage disks. Unlike an index (which is a separate lookup table), clustering physically organizes the table’s raw data to make querying specific ranges incredibly fast.
- Z-Ordering (Multi-dimensional Clustering): An advanced technique used in data lakes and lakehouses (like Delta Lake) to co-locate related information in the same set of physical files based on multiple columns, drastically reducing the amount of data read during complex queries.
- Compaction (Bin-packing): The automated maintenance process in data lakes/lakehouses of combining thousands of tiny data files into a few larger files. Processing engines operate much faster on large files than on millions of small ones.
- Vacuuming: The database maintenance process of permanently deleting obsolete data files (such as those left behind by updates, deletions, or failed operations) to free up storage space and reduce cloud storage costs.
Security, Privacy, & Compliance
- PII (Personally Identifiable Information): Any data that could potentially identify a specific individual (names, emails, IP addresses). Managing PII requires strict masking, encryption, and access controls within the data warehouse.
- Tokenization: A security measure often applied before data enters the warehouse. Sensitive data (like a credit card number) is swapped out for a randomly generated string of characters (a token). The warehouse only stores the token, rendering the data useless to hackers if breached.
- Encryption at Rest vs. In Transit: “At Rest” means the data files sitting on the storage disk are encrypted. “In Transit” means the data is encrypted while moving over the network (e.g., traveling from the ETL tool to the warehouse).
- Data Erasure (Right to be Forgotten): A compliance requirement under regulations like GDPR and CCPA. Data warehouses must have architectural mechanisms to completely and permanently purge a specific user’s historical data upon request without breaking the referential integrity of financial or aggregated facts.
The Modern Data Stack (MDS) & Engineering Patterns
- Modern Data Stack (MDS): A category of cloud-native data integration and analytics tools that emphasize the ELT paradigm, massive scalability, and modularity (using different specialized vendors for extraction, storage, transformation, and BI).
- Analytics Engineering: A discipline that bridges the gap between Data Engineering and Data Analysis. It focuses on taking raw data loaded into the warehouse and applying software engineering best practices (version control, automated testing) to build clean, ready-to-use business datasets.
- CI/CD for Data (Continuous Integration / Continuous Deployment): The practice of treating database schemas and SQL transformations as code. Changes are automatically tested in a staging environment before being deployed to the production data warehouse to prevent human error.
- Idempotency: A critical property of a well-engineered data pipeline. It means that no matter how many times you run the exact same data load or transformation process, the final result in the warehouse will be exactly the same (no duplicated data, no skewed metrics).
- Declarative Transformations: An approach (popularized by tools like dbt) where the engineer simply writes the
SELECTstatement defining what the final table should look like, and the tool automatically handles the complex underlying commands (theCREATE,INSERT,MERGE, orDROP) needed to make the warehouse match that definition.
Data Operations (DataOps) & Pipeline Management
- DataOps: An agile, collaborative data management practice focused on improving communication, integration, and automation of data flows between data engineers and data consumers, often applying software engineering CI/CD practices to data.
- Backfilling: The process of running a data pipeline for a historical time period. This is often done to populate a newly created table with old data, or to re-process historical data after fixing a bug in the transformation logic.
- Operator: In orchestration tools (like Apache Airflow), an operator represents a single, defined task within a pipeline (e.g., an operator specifically designed to execute a SQL script, or one designed to move a file from an SFTP server to cloud storage).
- Sensor: A specialized orchestration task designed to wait for a specific external event to occur (such as a file arriving in a folder, or another database finishing its load) before allowing the rest of the pipeline to continue.
- Watermarking: In streaming data architectures, a mechanism used to handle late-arriving data. It establishes a threshold (the “watermark”) that tells the system when it is safe to assume all data for a specific time window has arrived, allowing it to finalize calculations and move on.
Advanced Storage & Indexing Mechanics
- Bloom Filter: A highly space-efficient, probabilistic data structure used by query engines. It cannot tell you exactly where a piece of data is, but it can quickly and definitively tell the engine if a specific value does not exist within a massive block of data, preventing the system from wasting time scanning empty blocks.
- B-Tree (Balanced Tree) Index: The standard indexing structure used in traditional relational databases. It keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. (Often supplemented by Bitmap indexes in data warehousing).
- Micro-Partitioning: A proprietary storage technique used by some cloud data warehouses (like Snowflake) where data is automatically divided into millions of tiny, contiguous, immutable storage files behind the scenes, eliminating the need for engineers to manually define and maintain partition keys.
- Sharding: A database architecture pattern where a single massive table or database is horizontally partitioned into smaller, faster, more easily managed pieces called “shards,” which are then distributed across multiple physical servers to distribute the processing load.
Specialized BI, Reporting, & Delivery
- Embedded Analytics: The integration of data visualizations, dashboards, and reporting capabilities directly into other business applications (like a CRM, ERP, or custom web portal), so users do not have to leave their primary workflow to use a separate BI tool.
- Canned Report: A highly structured, pre-built, and typically static report designed to answer routine, recurring business questions. They are often generated and distributed automatically on a set schedule.
- KPI (Key Performance Indicator): A quantifiable, top-level metric used to evaluate how effectively a company is achieving key business objectives. The core purpose of most data warehouses is to provide a single, trusted source for calculating KPIs.
- Balanced Scorecard: A strategic management framework, often visualized in BI dashboards, that tracks organizational performance across multiple perspectives (typically financial, customer, internal process, and learning/growth) rather than just looking at revenue.
Privacy Engineering & Compliance
- Pseudonymization: A data privacy technique where sensitive personally identifiable information (PII) is replaced with artificial identifiers (pseudonyms). Crucially, the original data can be restored if the user has access to a secure “key.”
- Anonymization: A more severe privacy technique where personal identifiers are permanently destroyed or obscured. Unlike pseudonymization, true anonymization is entirely irreversible; it is impossible to trace the data back to an individual.
- Synthetic Data: Artificially generated data that mathematically mimics the statistical properties, relationships, and shape of real production data, but contains absolutely no real user information. It is used to safely test data warehouse pipelines and machine learning models without risking compliance breaches.
- Data Lineage Graph: A visual, interactive map (usually provided by a Data Catalog tool) that traces the exact journey of a data point. It shows the source system it originated from, the ETL scripts that transformed it, the warehouse tables it lives in, and the specific BI dashboards that ultimately display it.
Advanced Analytical SQL & Querying Concepts
- Window Functions: Advanced SQL functions that perform calculations across a specific set of rows (a “window”) related to the current row, without collapsing the results into a single row like standard aggregations do. Used heavily for running totals or moving averages.
- CTE (Common Table Expression): A temporary named result set created using a
WITHclause. It makes complex, deeply nested SQL queries much easier to read and maintain by breaking them down into modular, logical blocks. - Lead and Lag: Specific window functions crucial for time-series analysis in a data warehouse.
LAGallows a query to access a value from a previous row (e.g., comparing today’s sales to yesterday’s), whileLEADaccesses a value from a subsequent row. - Pivot and Unpivot: Relational operations used to transform data presentation.
PIVOTrotates data from rows into columns (turning unique values into column headers), whileUNPIVOTrotates columns back into rows, often used to normalize spreadsheet-style data loaded into the warehouse. - UDF (User-Defined Function): Custom, complex logic written by a data engineer (often in SQL, Python, or Java) that is saved within the database engine. It can be called like a standard SQL function to perform highly specific business calculations that native SQL cannot easily handle.
Master Data Management (MDM) & Entity Resolution
- Entity Resolution (Record Linkage): The complex data engineering process of identifying and merging multiple records across different systems that actually refer to the same real-world entity, even if they lack a shared unique identifier.
- Golden Record: The ultimate goal of Master Data Management. It is the single, cleansed, consolidated, and definitive version of a data entity (like a single “Customer Profile”) created by merging the best available information from multiple conflicting source systems.
- Survivorship Rules: The strict business logic used during the creation of a Golden Record. When two source systems provide conflicting data (e.g., CRM says the customer’s phone number is X, but the Billing system says Y), survivorship rules dictate which system “wins” and survives in the final record.
- Fuzzy Matching: An algorithmic technique used in Entity Resolution to identify text strings that are similar but not exactly identical (e.g., matching “Jon Doe” with “John Doe”, or catching typos in addresses) to help eliminate duplicate entities.
Event-Driven Architecture & Integration
- Message Broker (Message Queue): Infrastructure software (like Apache Kafka or RabbitMQ) that sits between operational systems and the data warehouse pipeline. It receives, stores, and distributes massive volumes of data events in real-time, preventing the pipeline from being overwhelmed by sudden spikes in data volume.
- Pub/Sub (Publish-Subscribe): A messaging pattern used in streaming data integration. A source system “publishes” an event (like a new user registration) to a central topic, and any data pipeline that is “subscribed” to that topic instantly receives the data to load into the warehouse.
- Webhook: A mechanism where a source application automatically sends a real-time HTTP payload to the data integration tool the exact moment an event happens, triggering an instant data pipeline run, rather than the data pipeline constantly polling the source asking if anything is new.
- Change Tracking: A lighter alternative to Change Data Capture (CDC). Instead of reading database transaction logs to find every single row change, Change Tracking relies on a simple system-updated timestamp column (e.g.,
last_modified_date) to extract only the rows updated since the last ETL run.
Infrastructure Resilience & Object Storage
- Object Storage: The foundational storage technology for Data Lakes and Cloud Data Warehouses (e.g., Amazon S3, Google Cloud Storage, Azure Blob). It stores data as “objects” in a flat structure with vast amounts of metadata, rather than in traditional file hierarchies or block storage, allowing for limitless scalability.
- Multi-Cloud Architecture: Designing a data warehousing ecosystem that distributes workloads across multiple public cloud providers (e.g., storing the data lake in AWS but running the warehouse compute engine in Google Cloud) to avoid vendor lock-in and negotiate better pricing.
- High Availability (HA): Architectural design that ensures the data warehouse remains accessible and operational almost 100% of the time, typically achieved by replicating the database nodes across different physical data centers (Availability Zones).
- RPO (Recovery Point Objective): A disaster recovery metric. In the event of a catastrophic system failure, it represents the maximum acceptable amount of data loss, measured in time (e.g., an RPO of 1 hour means the warehouse must be restored with data that is no more than 1 hour old).
- RTO (Recovery Time Objective): Another disaster recovery metric. It represents the maximum acceptable amount of downtime before the data warehouse must be fully restored and operational again after an outage.