🗄️ What is a NoSQL Database?
A NoSQL database (often meaning “Not Only SQL”) is a type of database designed to handle large volumes of unstructured or semi-structured data.
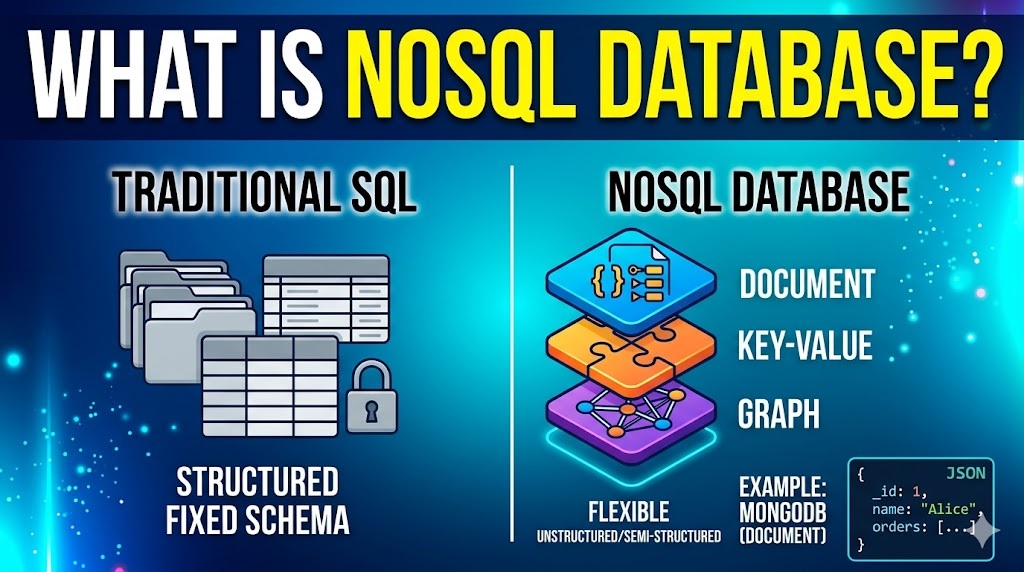
🔒 Unlike traditional relational databases (like MySQL or PostgreSQL) that store data in rigid, interconnected tables with strict rules, NoSQL databases store data in flexible, highly scalable formats.
🚀 They were built specifically to address the needs of modern applications, which often require rapid development, continuous updates, and the ability to scale horizontally across many servers.
⚖️ How NoSQL Differs from Traditional SQL
To understand NoSQL, it helps to see how it compares to traditional SQL databases:
| 📌 Feature | 🏢 SQL (Relational) | 📦 NoSQL (Non-Relational) |
| 🏗️ Structure | Tables with fixed rows and columns. | Flexible formats (Documents, Key-Value, Graphs). |
| 📋 Schema | Rigid: Must be defined before adding data. | Dynamic: You can add new data types on the fly. |
| 📈 Scaling | Vertical: You usually need to buy a bigger, more expensive server to handle more load. | Horizontal: You can simply add more cheap servers to distribute the load. |
| 🗃️ Data Type | Best for highly structured, predictable data. | Best for unstructured, fast-changing, or nested data. |
🧩 The Four Main Types of NoSQL Databases
NoSQL isn’t just one thing; it’s an umbrella term for several different data models:
- 📄 Document Databases (e.g., MongoDB, CouchDB): Store data in flexible, JSON-like documents. This is the most popular type for general web and app development.
- 🔑 Key-Value Stores (e.g., Redis, DynamoDB): The simplest type. Every single item in the database is stored as an attribute name (or “key”), together with its value (like a massive dictionary). Great for caching and user sessions.
- 🗂️ Wide-Column Stores (e.g., Cassandra, HBase): Store data in columns rather than rows, making them highly optimized for querying large datasets rapidly.
- 🕸️ Graph Databases (e.g., Neo4j): Focus entirely on the relationships between data points. Excellent for social networks, recommendation engines, and fraud detection.
💡 A Concrete Example: SQL vs. NoSQL
🛒 Imagine you are building an e-commerce app and need to store information about a user, including their multiple addresses and multiple hobbies.
🏢 The SQL Way (Relational)
Because SQL uses rigid tables, you cannot easily shove multiple addresses or hobbies into a single “User” row. You have to create multiple tables and link them together using ID numbers (Foreign Keys).
👤 Table 1: Users
| User_ID | Name | |
| 1 | Alice | alice@email.com |
📍 Table 2: Addresses
| Address_ID | User_ID | City | State |
| 101 | 1 | Seattle | WA |
| 102 | 1 | Portland | OR |
🎯 Table 3: Hobbies
| Hobby_ID | User_ID | Hobby_Name |
| 50 | 1 | Hiking |
| 51 | 1 | Coding |
⚠️ To get Alice’s full profile, the database has to run a complex “JOIN” operation across all three tables.
📦 The NoSQL Way (Document Database)
In a NoSQL Document database (like MongoDB), data is stored much like the objects you use in your application code. You can nest arrays and objects directly inside a single record.
JSON
{
"_id": "user_1",
"name": "Alice",
"email": "alice@email.com",
"addresses": [
{ "city": "Seattle", "state": "WA" },
{ "city": "Portland", "state": "OR" }
],
"hobbies": ["Hiking", "Coding"]
}
⭐ The Advantage here: All of Alice’s data is stored in one single place. When the application requests her profile, the database simply hands over this one document—no complex joining required. Furthermore, if you decide tomorrow that you want to add a twitter_handle to Alice’s profile, you can just add it to her document without having to alter the structure of the entire database.
🗄️ NoSQL డేటాబేస్ అంటే ఏమిటి?
NoSQL డేటాబేస్ (సాధారణంగా “Not Only SQL” అని అర్థం) అనేది పెద్ద మొత్తంలో అన్స్ట్రక్చర్డ్ (నిర్మాణాత్మకం కాని) లేదా సెమీ-స్ట్రక్చర్డ్ డేటాను నిర్వహించడానికి రూపొందించబడిన ఒక రకమైన డేటాబేస్.
🔒 కఠినమైన నియమాలతో దృఢమైన, ఒకదానితో ఒకటి అనుసంధానించబడిన టేబుల్స్లో డేటాను నిల్వ చేసే సాంప్రదాయ రిలేషనల్ డేటాబేస్ల (MySQL లేదా PostgreSQL వంటివి) వలె కాకుండా, NoSQL డేటాబేస్లు డేటాను అనువైన (flexible), అత్యంత స్కేలబుల్ ఫార్మాట్లలో నిల్వ చేస్తాయి.
🚀 ఆధునిక అప్లికేషన్ల అవసరాలను తీర్చడానికి ఇవి ప్రత్యేకంగా నిర్మించబడ్డాయి. వీటికి వేగవంతమైన అభివృద్ధి, నిరంతర అప్డేట్లు మరియు అనేక సర్వర్లలో అడ్డంగా (horizontally) స్కేల్ చేయగల సామర్థ్యం తరచుగా అవసరమవుతాయి.
⚖️ సాంప్రదాయ SQLకి మరియు NoSQLకి ఉన్న తేడాలు
NoSQLని అర్థం చేసుకోవడానికి, సాంప్రదాయ SQL డేటాబేస్లతో ఇది ఎలా పోల్చబడుతుందో చూడటం సహాయపడుతుంది:
| 📌 లక్షణం (Feature) | 🏢 SQL (రిలేషనల్) | 📦 NoSQL (నాన్-రిలేషనల్) |
| 🏗️ నిర్మాణం (Structure) | స్థిరమైన అడ్డు వరుసలు (rows) మరియు నిలువు వరుసలతో (columns) కూడిన టేబుల్స్. | అనువైన ఫార్మాట్లు (డాక్యుమెంట్లు, కీ-వాల్యూ, గ్రాఫ్లు). |
| 📋 స్కీమా (Schema) | దృఢమైనది: డేటాను జోడించే ముందే తప్పనిసరిగా నిర్వచించాలి. | డైనమిక్: మీరు ఎప్పటికప్పుడు కొత్త డేటా రకాలను సులభంగా జోడించవచ్చు. |
| 📈 స్కేలింగ్ (Scaling) | వర్టికల్ (నిలువు): ఎక్కువ లోడ్ను నిర్వహించడానికి మీరు సాధారణంగా పెద్ద, ఖరీదైన సర్వర్ను కొనుగోలు చేయాల్సి ఉంటుంది. | హారిజాంటల్ (అడ్డంగా): లోడ్ను పంపిణీ చేయడానికి మీరు కేవలం మరిన్ని చౌకైన సర్వర్లను జోడించవచ్చు. |
| 🗃️ డేటా రకం (Data Type) | అత్యంత నిర్మాణాత్మకమైన, ఊహించదగిన డేటాకు ఉత్తమమైనది. | నిర్మాణాత్మకం కాని, వేగంగా మారుతున్న లేదా నెస్టెడ్ (nested) డేటాకు ఉత్తమమైనది. |
🧩 NoSQL డేటాబేస్లలో నాలుగు ప్రధాన రకాలు
NoSQL అనేది కేవలం ఒక్కటే కాదు; ఇది అనేక విభిన్న డేటా మోడళ్లను సూచించే ఒక పదం:
- 📄 డాక్యుమెంట్ డేటాబేస్లు (ఉదా., MongoDB, CouchDB): ఫ్లెక్సిబుల్ అయిన JSON లాంటి డాక్యుమెంట్లలో డేటాను నిల్వ చేస్తాయి. సాధారణ వెబ్ మరియు యాప్ డెవలప్మెంట్ కోసం ఇది అత్యంత ప్రసిద్ధ రకం.
- 🔑 కీ-వాల్యూ స్టోర్స్ (ఉదా., Redis, DynamoDB): ఇది అత్యంత సరళమైన రకం. డేటాబేస్లోని ప్రతి అంశం దాని వాల్యూతో పాటు ఒక అట్రిబ్యూట్ పేరు (లేదా “కీ”) వలె నిల్వ చేయబడుతుంది (ఒక పెద్ద డిక్షనరీ లాగా). క్యాషింగ్ (caching) మరియు యూజర్ సెషన్లకు ఇవి చాలా గొప్పవి.
- 🗂️ వైడ్-కాలమ్ స్టోర్స్ (ఉదా., Cassandra, HBase): అడ్డు వరుసలకు బదులుగా డేటాను నిలువు వరుసలలో (columns) నిల్వ చేస్తాయి. ఇది పెద్ద డేటాసెట్లను వేగంగా క్వెరీ చేయడానికి వీటిని అత్యంత అనుకూలంగా మారుస్తుంది.
- 🕸️ గ్రాఫ్ డేటాబేస్లు (ఉదా., Neo4j): డేటా పాయింట్ల మధ్య ఉన్న సంబంధాలపై పూర్తిగా దృష్టి పెడతాయి. సోషల్ నెట్వర్క్లు, రికమండేషన్ ఇంజన్లు మరియు ఫ్రాడ్ డిటెక్షన్ (మోసాల గుర్తింపు) కోసం ఇవి అద్భుతంగా పనిచేస్తాయి.
💡 ఒక స్పష్టమైన ఉదాహరణ: SQL vs. NoSQL
🛒 మీరు ఒక ఈ-కామర్స్ యాప్ను నిర్మిస్తున్నారని మరియు యూజర్ యొక్క బహుళ అడ్రస్లు మరియు బహుళ హాబీలతో సహా వారి సమాచారాన్ని నిల్వ చేయాల్సి ఉందని ఊహించుకోండి.
🏢 SQL విధానం (రిలేషనల్)
SQL కఠినమైన టేబుల్స్ను ఉపయోగిస్తుంది కాబట్టి, మీరు బహుళ అడ్రస్లు లేదా హాబీలను ఒకే “User” అడ్డు వరుసలోకి సులభంగా నెట్టలేరు. మీరు తప్పనిసరిగా బహుళ టేబుల్స్ను సృష్టించాలి మరియు ID నంబర్లను (ఫారిన్ కీస్ – Foreign Keys) ఉపయోగించి వాటిని ఒకదానితో ఒకటి అనుసంధానించాలి.
👤 టేబుల్ 1: Users
| User_ID | Name | |
| 1 | Alice | alice@email.com |
📍 టేబుల్ 2: Addresses
| Address_ID | User_ID | City | State |
| 101 | 1 | Seattle | WA |
| 102 | 1 | Portland | OR |
🎯 టేబుల్ 3: Hobbies
| Hobby_ID | User_ID | Hobby_Name |
| 50 | 1 | Hiking |
| 51 | 1 | Coding |
⚠️ ఆలిస్ (Alice) యొక్క పూర్తి ప్రొఫైల్ను పొందడానికి, డేటాబేస్ మూడు టేబుల్స్ అంతటా ఒక సంక్లిష్టమైన “JOIN” ఆపరేషన్ను రన్ చేయాలి.
📦 NoSQL విధానం (డాక్యుమెంట్ డేటాబేస్)
NoSQL డాక్యుమెంట్ డేటాబేస్లో (MongoDB వలె), మీరు మీ అప్లికేషన్ కోడ్లో ఉపయోగించే ఆబ్జెక్ట్ల మాదిరిగానే డేటా నిల్వ చేయబడుతుంది. మీరు ఒకే రికార్డ్ లోపల నేరుగా శ్రేణులను (arrays) మరియు ఆబ్జెక్ట్లను నెస్ట్ (nest) చేయవచ్చు.
JSON
{
"_id": "user_1",
"name": "Alice",
"email": "alice@email.com",
"addresses": [
{ "city": "Seattle", "state": "WA" },
{ "city": "Portland", "state": "OR" }
],
"hobbies": ["Hiking", "Coding"]
}
⭐ ఇక్కడ ప్రయోజనం: ఆలిస్ యొక్క డేటా అంతా ఒకే చోట నిల్వ చేయబడింది. అప్లికేషన్ ఆమె ప్రొఫైల్ను అభ్యర్థించినప్పుడు, డేటాబేస్ ఈ ఒక్క డాక్యుమెంట్ను మాత్రమే అందజేస్తుంది—ఎలాంటి సంక్లిష్టమైన జాయినింగ్ (joining) అవసరం లేదు. ఇంకా, మీరు రేపు ఆలిస్ ప్రొఫైల్కు ట్విట్టర్ హ్యాండిల్ని (twitter_handle) జోడించాలని నిర్ణయించుకుంటే, మొత్తం డేటాబేస్ యొక్క నిర్మాణాన్ని మార్చకుండానే మీరు దానిని ఆమె డాక్యుమెంట్కు సులభంగా జోడించవచ్చు.