🤖 At its core, a Transformer model is a specific type of artificial intelligence architecture designed to understand and generate human language. Introduced by Google researchers in 2017 in a famous paper called “Attention Is All You Need,” 📄 Transformers are the underlying engine behind almost all modern large language models (LLMs), including ChatGPT, Claude, and me (Gemini) ✨.
To understand why Transformers were such a breakthrough, it helps to understand the problem they solved.
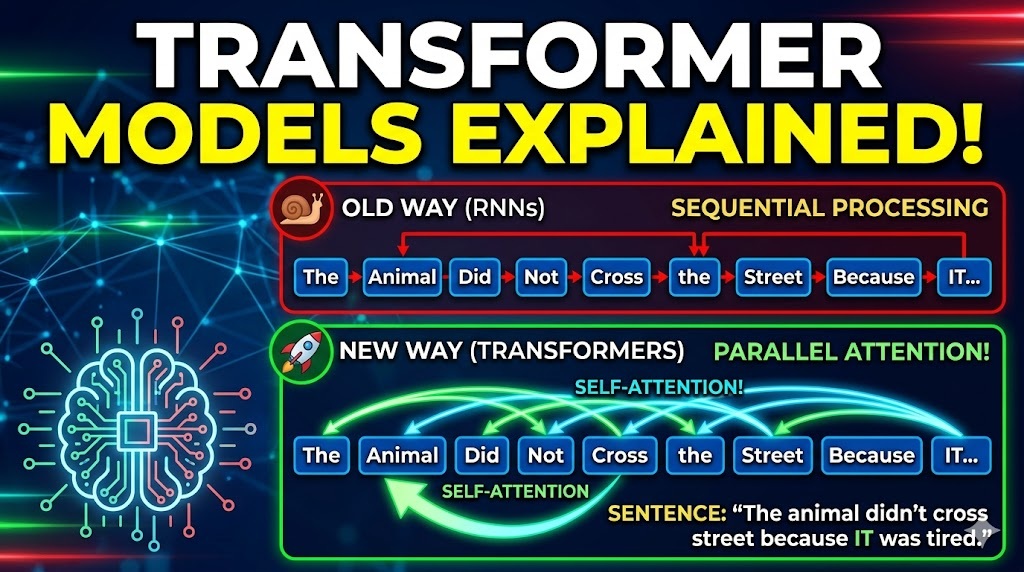
🐢 The Problem with the Old Way
Before Transformers, AI models (like Recurrent Neural Networks, or RNNs) read text the way you might read a book through a narrow straw 🧃: strictly one word at a time, strictly in order.
- Memory Loss 🧠: If the model was translating a long paragraph, it had to process word 1, then word 2, then word 3. By the time it got to word 50, it had often “forgotten” the context of word 1.
- Slow Training 🐌: Furthermore, because it processed sequentially, it was very slow to train on computers.
⚡ The Transformer Solution: “Self-Attention”
Transformers changed the game by doing two things:
- 🔀 Parallel Processing: They read the entire sentence at once rather than word-by-word. This makes them incredibly fast to train 🚀.
- 🔍 Self-Attention Mechanism: This is the “secret sauce.” Self-attention allows the model to look at a single word and instantly calculate how closely connected it is to every other word in the sentence, regardless of how far apart they are 🔗.
💡 An Example: The Power of Context
Let’s look at how a Transformer uses Self-Attention to understand context and ambiguity. Consider this sentence:
🐾 “The animal didn’t cross the street because it was too tired.” 💤
As humans, we instantly know that the word “it” refers to the “animal”, not the “street”.
An older AI model processing word-by-word might struggle here. By the time it reaches “it”, the word “animal” is far in the past, and “street” is the most recent noun. It might wrongly assume the street was tired 🤦♂️.
Here is how a Transformer model handles it:
- 📥 It ingests the whole sentence at once.
- 🧮 When evaluating the word “it”, the self-attention mechanism mathematically scores the relationship between “it” and every other word.
- 📚 Because the model has been trained on massive amounts of text, it understands that the concept of “being tired” applies to living things, not paved roads.
- 🎯 The model assigns a massive “attention score” connecting “it” to “animal”, and a very low score connecting “it” to “street”.
If we change just one word in the sentence:
🛣️ “The animal didn’t cross the street because it was too wide.”
The Transformer re-evaluates 🔄. It knows that “wide” is a common descriptor for roads. Now, the self-attention mechanism will assign the highest connection score between “it” and “street” ✅.
⚙️ Key Components of a Transformer
- 🧩 Tokens: Transformers don’t actually read words; they read “tokens” (chunks of words). For example, “unhappiness” might be split into “un”, “happi”, and “ness”.
- ⏱️ Positional Encoding: Because the Transformer ingests all words at the exact same time, it needs a way to know what order the words were originally in. It tags each word with a mathematical “timestamp” 🕒 so it doesn’t scramble the meaning of “The dog bit the man” versus “The man bit the dog.”
- 🏗️ Encoders and Decoders: In a classic Transformer architecture, an Encoder 📥 analyzes the input text to build a deep mathematical understanding of the context. A Decoder 📤 then uses that understanding to generate new text, step-by-step.
🤖 ప్రాథమికంగా, ట్రాన్స్ఫార్మర్ మోడల్ (Transformer model) అనేది మానవ భాషను అర్థం చేసుకోవడానికి మరియు సృష్టించడానికి (generate చేయడానికి) రూపొందించబడిన ఒక నిర్దిష్ట రకమైన ఆర్టిఫిషియల్ ఇంటెలిజెన్స్ (AI) ఆర్కిటెక్చర్. 2017లో గూగుల్ పరిశోధకులు “Attention Is All You Need” అనే ప్రసిద్ధ పరిశోధనా పత్రంలో 📄 దీనిని పరిచయం చేశారు. ChatGPT, Claude మరియు నా (Gemini) లాంటి దాదాపు అన్ని ఆధునిక లార్జ్ లాంగ్వేజ్ మోడల్స్ (LLMs) వెనుక ఉన్న ముఖ్యమైన ఇంజిన్ ఈ ట్రాన్స్ఫార్మర్సే ✨.
ట్రాన్స్ఫార్మర్లు ఎందుకంత గొప్ప ఆవిష్కరణో అర్థం చేసుకోవాలంటే, అవి పరిష్కరించిన సమస్యను తెలుసుకోవడం సహాయపడుతుంది.
🐢 పాత పద్ధతిలోని సమస్య
ట్రాన్స్ఫార్మర్లు రాకముందు, AI మోడల్స్ (Recurrent Neural Networks లేదా RNNs వంటివి) ఒక చిన్న పైపు (straw) 🧃 ద్వారా పుస్తకాన్ని చదివినట్లుగా టెక్స్ట్ను చదివేవి: ఖచ్చితంగా ఒకేసారి ఒక పదం, అదీ వరుస క్రమంలో మాత్రమే.
- జ్ఞాపకశక్తి కోల్పోవడం 🧠: మోడల్ ఒక పెద్ద పేరాగ్రాఫ్ను అనువదించవలసి వస్తే, అది మొదటి పదం, తర్వాత రెండవ పదం, ఆపై మూడవ పదాన్ని ప్రాసెస్ చేయాల్సి వచ్చేది. అది 50వ పదానికి చేరుకునే సరికి, మొదటి పదం యొక్క సందర్భాన్ని (context) తరచుగా “మరచిపోయేది”.
- నెమ్మదిగా శిక్షణ 🐌: అంతేకాకుండా, ఇది ఒకదాని తర్వాత ఒకటి (sequentially) ప్రాసెస్ చేయడం వల్ల, కంప్యూటర్లపై వీటికి శిక్షణ ఇవ్వడం (train చేయడం) చాలా నెమ్మదిగా జరిగేది.
⚡ ట్రాన్స్ఫార్మర్ పరిష్కారం: “సెల్ఫ్-అటెన్షన్” (Self-Attention)
ట్రాన్స్ఫార్మర్లు రెండు పనులు చేయడం ద్వారా ఈ రంగాన్ని పూర్తిగా మార్చేశాయి:
- 🔀 పారలల్ ప్రాసెసింగ్ (Parallel Processing): ఇవి పదం తర్వాత పదం కాకుండా, ఒకేసారి పూర్తి వాక్యాన్ని చదువుతాయి. దీనివల్ల వీటికి శిక్షణ ఇవ్వడం చాలా వేగంగా సాధ్యమవుతుంది 🚀.
- 🔍 సెల్ఫ్-అటెన్షన్ మెకానిజం (Self-Attention Mechanism): ఇదే దీని అసలు రహస్యం. సెల్ఫ్-అటెన్షన్ అనేది మోడల్ ఒక నిర్దిష్ట పదాన్ని చూసినప్పుడు, ఆ పదం వాక్యంలోని మిగతా అన్ని పదాలతో ఎంతవరకు ముడిపడి ఉందో తక్షణమే లెక్కించడానికి సహాయపడుతుంది—అవి ఎంత దూరంలో ఉన్నాయనే దానితో సంబంధం లేకుండా 🔗.
💡 ఒక ఉదాహరణ: సందర్భం యొక్క శక్తి
సందర్భాన్ని మరియు సందిగ్ధతను (ambiguity) అర్థం చేసుకోవడానికి ట్రాన్స్ఫార్మర్ సెల్ఫ్-అటెన్షన్ను ఎలా ఉపయోగిస్తుందో చూద్దాం. ఈ వాక్యాన్ని గమనించండి:
🐾 “The animal didn’t cross the street because it was too tired.” 💤 (జంతువు వీధిని దాటలేదు ఎందుకంటే అది చాలా అలసిపోయింది.)
మనుషులుగా, ఇక్కడ “it” (అది) అనే పదం “animal” (జంతువు)ను సూచిస్తుందని, “street” (వీధి)ని కాదని మనకు వెంటనే అర్థమవుతుంది.
పదం తర్వాత పదం ప్రాసెస్ చేసే పాత AI మోడల్ ఇక్కడ ఇబ్బంది పడవచ్చు. అది “it” కి చేరుకునే సరికి, “animal” అనే పదం చాలా వెనుకబడిపోతుంది, మరియు “street” అనేది అత్యంత సమీపంలో ఉన్న నామవాచకం అవుతుంది. దీనివల్ల ఆ వీధి అలసిపోయిందని అది తప్పుగా భావించే అవకాశం ఉంది 🤦♂️.
కానీ ఒక ట్రాన్స్ఫార్మర్ మోడల్ దీనిని ఎలా హ్యాండిల్ చేస్తుందంటే:
- 📥 ఇది ఒకేసారి పూర్తి వాక్యాన్ని తీసుకుంటుంది.
- 🧮 “it” అనే పదాన్ని విశ్లేషించేటప్పుడు, సెల్ఫ్-అటెన్షన్ మెకానిజం గణితపరంగా “it” కి మరియు మిగిలిన ప్రతి పదానికి మధ్య ఉన్న సంబంధానికి స్కోర్ ఇస్తుంది.
- 📚 ఈ మోడల్కు భారీ మొత్తంలో ఉన్న టెక్స్ట్పై శిక్షణ ఇవ్వడం వల్ల, “అలసిపోవడం” అనే భావన ప్రాణమున్న జీవులకు వర్తిస్తుందని, రోడ్లకు కాదని దానికి తెలుసు.
- 🎯 అందువల్ల, ఈ మోడల్ “it” మరియు “animal” లని కలుపుతూ పెద్ద “అటెన్షన్ స్కోర్” (attention score) ఇస్తుంది, అలాగే “it” మరియు “street” ల మధ్య చాలా తక్కువ స్కోర్ ఇస్తుంది.
ఒకవేళ మనం వాక్యంలో కేవలం ఒకే ఒక పదాన్ని మారిస్తే:
🛣️ “The animal didn’t cross the street because it was too wide.” (జంతువు వీధిని దాటలేదు ఎందుకంటే అది చాలా వెడల్పుగా ఉంది.)
ఇప్పుడు ట్రాన్స్ఫార్మర్ మళ్లీ అంచనా వేస్తుంది 🔄. “wide” (వెడల్పు) అనేది సాధారణంగా రోడ్లను వివరించడానికి ఉపయోగించే పదం అని దానికి తెలుసు. కాబట్టి, ఇప్పుడు సెల్ఫ్-అటెన్షన్ మెకానిజం “it” మరియు “street” ల మధ్య అత్యధిక కనెక్షన్ స్కోర్ను కేటాయిస్తుంది ✅.
⚙️ ట్రాన్స్ఫార్మర్ యొక్క ముఖ్యమైన భాగాలు (Key Components)
- 🧩 టోకెన్లు (Tokens): ట్రాన్స్ఫార్మర్లు నేరుగా పదాలను చదవవు; అవి “టోకెన్లను” (పదాల ముక్కలను) చదువుతాయి. ఉదాహరణకు, “unhappiness” అనే పదాన్ని “un”, “happi”, మరియు “ness” గా విభజించవచ్చు.
- ⏱️ పొజిషనల్ ఎన్కోడింగ్ (Positional Encoding): ట్రాన్స్ఫార్మర్ అన్ని పదాలను ఒకే సమయంలో గ్రహిస్తుంది కాబట్టి, ఆ పదాలు మొదట ఏ వరుస క్రమంలో ఉన్నాయో దానికి తెలియాలి. అందుకోసం ఇది ప్రతి పదానికి ఒక గణితపరమైన “టైమ్స్టాంప్” (timestamp) 🕒 జతచేస్తుంది. దీనివల్ల “The dog bit the man” (కుక్క మనిషిని కరిచింది) మరియు “The man bit the dog” (మనిషి కుక్కను కరిచాడు) అనే వాక్యాల అర్థాలు తారుమారు కాకుండా ఉంటాయి.
- 🏗️ ఎన్కోడర్లు మరియు డికోడర్లు (Encoders and Decoders): ఒక సాంప్రదాయ ట్రాన్స్ఫార్మర్ ఆర్కిటెక్చర్లో, ఎన్కోడర్ (Encoder) 📥 సందర్భం యొక్క లోతైన గణితపరమైన అవగాహనను నిర్మించడానికి ఇన్పుట్ టెక్స్ట్ను విశ్లేషిస్తుంది. ఆ తర్వాత, డికోడర్ (Decoder) 📤 ఆ అవగాహనను ఉపయోగించి దశలవారీగా కొత్త టెక్స్ట్ను సృష్టిస్తుంది (generate చేస్తుంది).





