🌐 Understanding Data Mesh
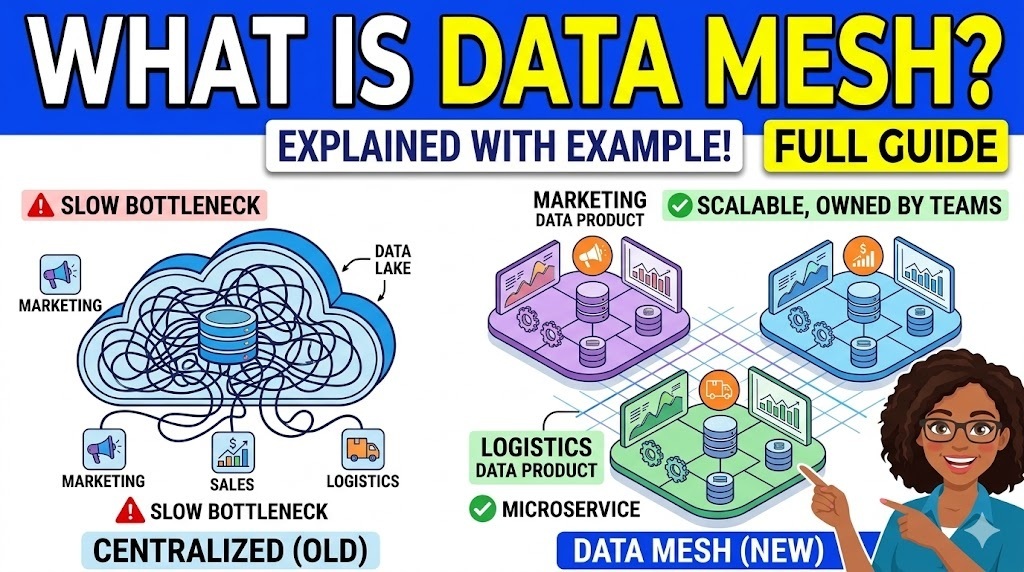
At its core, a Data Mesh is a decentralized approach to managing analytical data. Instead of funneling all of a company’s data into a single, massive, centrally managed hub (like a data lake or data warehouse), a Data Mesh distributes ownership of the data to the specific teams or “domains” that actually create and understand it.
💡 Why it matters: It was introduced to solve a common bottleneck: centralized data teams getting overwhelmed by requests from all over the company, slowing down the organization’s ability to use data effectively.
🏛️ The Four Core Principles
To truly be considered a Data Mesh, a data architecture must be built on four foundational pillars:
- 🏢 Domain-Oriented Ownership: Data is owned by the business teams that generate it. For instance, the marketing team owns the marketing data; the logistics team owns the shipping data.
- 📦 Data as a Product: Teams treat their data like a product they are providing to the rest of the company. This means the data must be high-quality, easily discoverable, securely accessible, and trustworthy.
- ⚙️ Self-Serve Data Infrastructure: A centralized platform team provides the underlying tools (databases, pipelines, access controls). This allows domain teams to easily build, host, and share their data products without needing to be infrastructure experts.
- ⚖️ Federated Computational Governance: A set of company-wide standards ensures that all these different, decentralized data products can still connect and work together securely, maintaining regulatory compliance and interoperability across the board.
🛒 Example: An E-Commerce Company
Let’s look at how an online retailer might handle their data under a traditional model versus a Data Mesh model.
| 📌 Feature | 🏢 The Old Way (Centralized) | 🕸️ The Data Mesh Way (Decentralized) |
| 🏗️ The Setup | Sales, Inventory, and Shipping all dump raw data into one giant central data warehouse. | The Sales, Inventory, and Shipping teams each manage their own distinct data. |
| ⏳ The Bottleneck | The central Data Engineering team has to clean, organize, and serve all that data to business analysts. They quickly become overwhelmed. | There is no central bottleneck. Each domain team cleans, packages, and serves their own data. |
| 🚀 The Result | If the Finance team needs a report combining sales and shipping, they wait weeks for the central IT team to build the required data pipeline. | The Finance team simply connects to the “Sales Data Product” and “Shipping Data Product” APIs directly to build their report instantly. |
🎯 Key Takeaway: In the Data Mesh example, the Sales team acts as the domain experts. Because they understand what a “completed transaction” actually means much better than a central IT team would, they are the best equipped to package that data accurately for the rest of the company to consume.
🌐 డేటా మెష్ను అర్థం చేసుకోవడం
ముఖ్యంగా, డేటా మెష్ (Data Mesh) అనేది విశ్లేషణాత్మక డేటాను (analytical data) నిర్వహించడానికి ఒక వికేంద్రీకృత (decentralized) విధానం. ఒక కంపెనీ డేటా మొత్తాన్ని ఒకే భారీ, కేంద్రీకృత హబ్లోకి (డేటా లేక్ లేదా డేటా వేర్హౌస్ లాగా) పంపే బదులు, ఆ డేటాను వాస్తవంగా సృష్టించే మరియు అర్థం చేసుకునే నిర్దిష్ట బృందాలకు లేదా “డొమైన్లకు” డేటా మెష్ ఆ డేటా యాజమాన్యాన్ని (ownership) పంపిణీ చేస్తుంది.
💡 ఎందుకు ముఖ్యమంటే: ఇది ఒక సాధారణ అడ్డంకిని (bottleneck) పరిష్కరించడానికి ప్రవేశపెట్టబడింది: కేంద్రీకృత డేటా బృందాలు కంపెనీ అంతటి నుండి వచ్చే అభ్యర్థనలతో అధిక భారాన్ని ఎదుర్కోవడం, తద్వారా సంస్థ డేటాను సమర్థవంతంగా ఉపయోగించుకునే సామర్థ్యం నెమ్మదించడం.
🏛️ నాలుగు ప్రధాన సూత్రాలు
నిజమైన డేటా మెష్గా పరిగణించబడాలంటే, డేటా ఆర్కిటెక్చర్ నాలుగు పునాది స్తంభాలపై నిర్మించబడాలి:
- 🏢 డొమైన్-ఓరియెంటెడ్ ఓనర్షిప్ (Domain-Oriented Ownership): డేటాను సృష్టించే వ్యాపార బృందాలకే దాని యాజమాన్యం ఉంటుంది. ఉదాహరణకు, మార్కెటింగ్ బృందానికి మార్కెటింగ్ డేటాపై, లాజిస్టిక్స్ బృందానికి షిప్పింగ్ డేటాపై యాజమాన్యం ఉంటుంది.
- 📦 ఉత్పత్తిగా డేటా (Data as a Product): బృందాలు తమ డేటాను కంపెనీలోని మిగిలిన వారికి అందించే ఒక ఉత్పత్తి (ప్రొడక్ట్) లాగా పరిగణిస్తాయి. అంటే డేటా అధిక-నాణ్యతతో, సులభంగా కనుగొనగలిగేలా, సురక్షితంగా యాక్సెస్ చేయడానికి వీలుగా మరియు నమ్మదగినదిగా ఉండాలి.
- ⚙️ సెల్ఫ్-సర్వ్ డేటా ఇన్ఫ్రాస్ట్రక్చర్ (Self-Serve Data Infrastructure): ఒక కేంద్రీకృత ప్లాట్ఫారమ్ బృందం ప్రాథమిక సాధనాలను (డేటాబేస్లు, పైప్లైన్లు, యాక్సెస్ కంట్రోల్స్) అందిస్తుంది. దీని వలన డొమైన్ బృందాలు మౌలిక సదుపాయాల (infrastructure) నిపుణులు కానవసరం లేకుండానే తమ డేటా ఉత్పత్తులను సులభంగా నిర్మించడానికి, హోస్ట్ చేయడానికి మరియు పంచుకోవడానికి వీలవుతుంది.
- ⚖️ ఫెడరేటెడ్ కంప్యూటేషనల్ గవర్నెన్స్ (Federated Computational Governance): కంపెనీ-వ్యాప్త ప్రమాణాల (standards) సమితి ఈ విభిన్న, వికేంద్రీకృత డేటా ఉత్పత్తులన్నీ సురక్షితంగా కనెక్ట్ అయ్యేలా మరియు కలిసి పనిచేసేలా నిర్ధారిస్తుంది. అలాగే నిబంధనలకు కట్టుబడి ఉండటాన్ని (regulatory compliance) మరియు ఇంటర్ఆపెరాబిలిటీని అంతటా నిర్వహిస్తుంది.
🛒 ఉదాహరణ: ఒక ఈ-కామర్స్ కంపెనీ
సాంప్రదాయ పద్ధతి వర్సెస్ డేటా మెష్ పద్ధతిలో ఒక ఆన్లైన్ రిటైలర్ తమ డేటాను ఎలా నిర్వహిస్తారో చూద్దాం.
| 📌 ఫీచర్ (Feature) | 🏢 పాత పద్ధతి (కేంద్రీకృతం) | 🕸️ డేటా మెష్ పద్ధతి (వికేంద్రీకృతం) |
| 🏗️ విధానం (The Setup) | సేల్స్, ఇన్వెంటరీ మరియు షిప్పింగ్ అంతా ముడి (raw) డేటాను ఒక భారీ కేంద్రీకృత డేటా వేర్హౌస్లో వేస్తాయి. | సేల్స్, ఇన్వెంటరీ మరియు షిప్పింగ్ బృందాలు ఒక్కొక్కటి తమ సొంత మరియు ప్రత్యేకమైన డేటాను నిర్వహిస్తాయి. |
| ⏳ అడ్డంకి (The Bottleneck) | కేంద్రీకృత డేటా ఇంజనీరింగ్ బృందం ఆ డేటా మొత్తాన్ని శుభ్రం చేసి, ఆర్గనైజ్ చేసి వ్యాపార విశ్లేషకులకు అందించాలి. వారిపై త్వరగా భారం పెరుగుతుంది. | ఇక్కడ కేంద్రీకృత అడ్డంకి ఉండదు. ప్రతి డొమైన్ బృందం తమ సొంత డేటాను శుభ్రం చేస్తుంది, ప్యాకేజీ చేస్తుంది మరియు సర్వ్ చేస్తుంది. |
| 🚀 ఫలితం (The Result) | ఫైనాన్స్ బృందానికి సేల్స్ మరియు షిప్పింగ్ కలిపి ఒక రిపోర్ట్ అవసరమైతే, అవసరమైన డేటా పైప్లైన్ను నిర్మించడానికి సెంట్రల్ ఐటీ బృందం కోసం వారాల పాటు వేచి ఉండాల్సి వస్తుంది. | ఫైనాన్స్ బృందం వెంటనే తమ రిపోర్ట్ను రూపొందించడానికి నేరుగా “సేల్స్ డేటా ప్రొడక్ట్” మరియు “షిప్పింగ్ డేటా ప్రొడక్ట్” APIలకు సులభంగా కనెక్ట్ అవుతుంది. |
🎯 ముఖ్యమైన విషయం: డేటా మెష్ ఉదాహరణలో, సేల్స్ బృందం డొమైన్ నిపుణులుగా వ్యవహరిస్తుంది. “పూర్తయిన లావాదేవీ (completed transaction)” అంటే ఏమిటో సెంట్రల్ ఐటీ బృందం కంటే వారికే బాగా అర్థం అవుతుంది కాబట్టి, కంపెనీలోని మిగిలిన వారు వినియోగించుకోవడానికి ఆ డేటాను ఖచ్చితంగా ప్యాకేజ్ చేయడానికి వారు అత్యుత్తమ సామర్థ్యం కలిగి ఉంటారు.