🏠 Understanding the Data Lakehouse
A Data Lakehouse is a modern data management architecture that combines the best features of two traditional systems: the Data Warehouse and the Data Lake.
To understand the Lakehouse, it helps to see what it’s replacing:
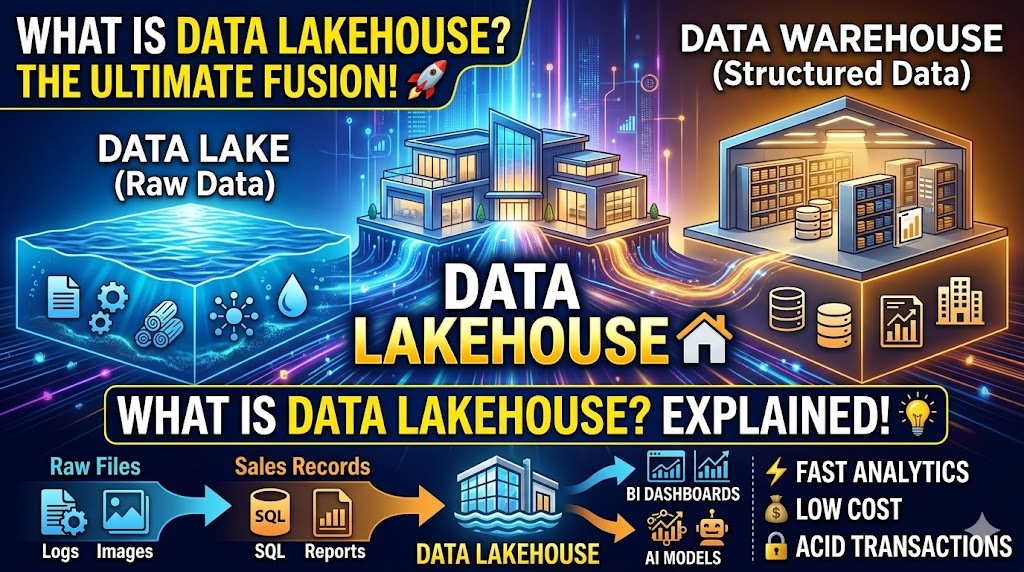
- 🏢 Data Warehouse: Highly structured, great for business intelligence (BI), but expensive and struggles with unstructured data (like images or raw logs).
- 🌊 Data Lake: Stores massive amounts of raw data cheaply, but often lacks organization, making it difficult to keep data “clean” or perform fast queries (the “data swamp” problem).
💡 A Lakehouse implements a metadata layer on top of a low-cost data lake, allowing for the performance and ACID transactions of a warehouse with the flexibility of a lake.
🚀 Key Features of a Lakehouse
- 🛡️ ACID Transactions: Ensures that data stays consistent even when multiple parties are reading and writing at the same time.
- 📋 Schema Enforcement: Prevents “junk” data from entering the system by requiring it to follow a specific format.
- 🤝 Unified Support: It serves both Data Scientists (who need raw data for Machine Learning) and Business Analysts (who need structured data for dashboards) from a single source.
- 💰 Low-Cost Storage: It uses inexpensive cloud object storage (like Amazon S3 or Google Cloud Storage) rather than expensive proprietary hardware.
🛒 Practical Example: A Global E-commerce Platform
Imagine a massive online retailer like Amazon or eBay. They deal with two very different types of data:
- 📊 Structured Data: Sales records, customer IDs, and inventory counts.
- 🖼️ Unstructured Data: Product images, customer review videos, and clickstream logs.
🔄 The “Old” Way (Two Systems)
The company would store sales records in a Data Warehouse for the finance team. Meanwhile, clickstream logs and images would be dumped into a Data Lake for the AI team. This creates “data silos” where teams can’t easily share info, and data must be moved back and forth constantly.
🎯 The Lakehouse Way (One System)
With a Data Lakehouse, all that data stays in one place.
- 📈 The Finance Team runs a SQL query on the Lakehouse to see yesterday’s revenue. The metadata layer ensures the data is accurate.
- 🤖 The AI Team accesses the exact same system to pull raw images and logs to train a new visual search tool.
✅ The Result
The company saves money on storage, reduces time spent moving data, and ensures everyone is looking at the same “version of the truth.”
🏠 Data Lakehouse గురించి తెలుసుకుందాం
Data Lakehouse అనేది ఒక modern data management architecture. ఇది మనకున్న traditional systems అయిన Data Warehouse మరియు Data Lake లలోని best features ని కలిపి రూపొందించబడింది.
దీని గురించి క్లియర్ గా అర్థం చేసుకోవాలంటే, ఇది వేటిని replace చేస్తుందో చూడాలి:
- 🏢 Data Warehouse: ఇది highly structured గా ఉంటుంది. Business Intelligence (BI) రిపోర్ట్స్ కి చాలా బాగుంటుంది, కానీ ఇది చాలా expensive. పైగా images లేదా raw logs వంటి unstructured data ని handle చేయడం దీనికి చాలా కష్టం.
- 🌊 Data Lake: ఇందులో massive amounts of raw data ని చాలా తక్కువ ఖర్చుతో store చేయవచ్చు. కానీ దీనికి ప్రాపర్ organization ఉండదు, అందుకే డేటాని “clean” గా ఉంచడం లేదా fast queries రన్ చేయడం కష్టం అవుతుంది (దీన్నే “data swamp” problem అంటారు).
💡 ఒక Lakehouse అనేది low-cost data lake పైన ఒక metadata layer ని ఏర్పాటు చేస్తుంది. దీనివల్ల Warehouse లాంటి performance మరియు ACID transactions వస్తాయి, అలాగే Lake లాంటి flexibility కూడా దక్కుతుంది.
🚀 Key Features of a Lakehouse
- 🛡️ ACID Transactions: ఒకే సమయంలో చాలా మంది data ని read లేదా write చేసినప్పుడు, data ఎక్కడా mismatch అవ్వకుండా consistency ని కాపాడుతుంది.
- 📋 Schema Enforcement: డేటా ఒక specific format లోనే ఉండాలని నియంత్రిస్తుంది. దీనివల్ల “junk” data సిస్టమ్ లోపలికి రాకుండా ఉంటుంది.
- 🤝 Unified Support: ఇది ఒకే source నుండి Data Scientists (for Machine Learning) కి మరియు Business Analysts (for dashboards) కి కావలసిన డేటాని అందిస్తుంది.
- 💰 Low-Cost Storage: ఇది ఖరీదైన hardware కాకుండా, Amazon S3 లేదా Google Cloud Storage లాంటి inexpensive cloud object storage ని వాడుకుంటుంది.
🛒 Practical Example: ఒక Global E-commerce Platform
Amazon లేదా eBay లాంటి ఒక పెద్ద online retailer ని ఊహించుకోండి. వారు రెండు రకాల డేటాని మేనేజ్ చేయాలి:
- 📊 Structured Data: Sales records, customer IDs, మరియు inventory వివరాలు.
- 🖼️ Unstructured Data: Product images, customer review videos, మరియు clickstream logs.
🔄 పాత పద్ధతి (Two Systems)
ఆ కంపెనీ sales records ని రిపోర్ట్స్ కోసం Data Warehouse లో దాస్తుంది. అదే సమయంలో images మరియు logs ని AI టీమ్ కోసం Data Lake లో పడేస్తుంది. దీనివల్ల రెండు టీమ్స్ మధ్య డేటా షేరింగ్ కష్టమవుతుంది, దీన్నే “data silos” అంటారు. డేటాని ఒక చోటు నుండి ఇంకో చోటుకి పదే పదే మార్చాల్సి వస్తుంది.
🎯 Lakehouse పద్ధతి (One System)
Data Lakehouse తో మొత్తం డేటా ఒకే చోట ఉంటుంది.
- 📈 Finance Team: నిన్నటి revenue ఎంతో తెలుసుకోవడానికి Lakehouse మీద ఒక SQL query రన్ చేస్తారు. Metadata layer వల్ల వారికి ఖచ్చితమైన (accurate) డేటా అందుతుంది.
- 🤖 AI Team: అదే సిస్టమ్ నుండి raw images మరియు logs ని తీసుకుని కొత్త visual search టూల్ ని ట్రైన్ చేస్తారు.
✅ The Result
కంపెనీకి storage ఖర్చు తగ్గుతుంది, డేటాని ఇటు అటు మార్చే టైమ్ సేవ్ అవుతుంది, మరియు అందరూ ఒకే “version of the truth” ని చూస్తారు.





