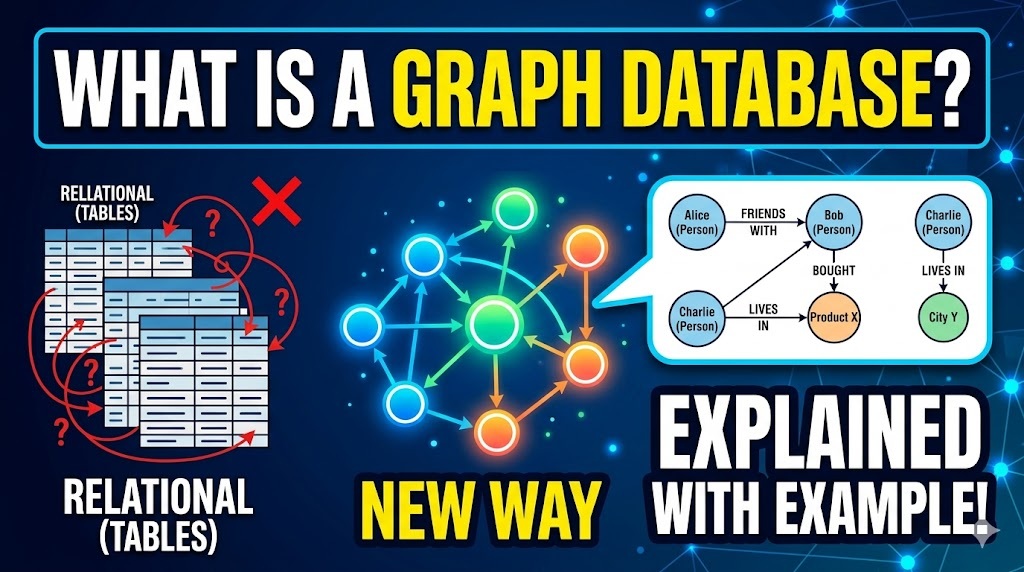
A Graph Database is a type of NoSQL database that uses graph structures to represent and store data. Unlike traditional relational databases that rely on rigid tables, graph databases prioritize the relationships between data points.
💡 Core Philosophy: In a graph database, the connections between data are just as important as the data itself.
🛠️ Key Components
🔵 Nodes (Vertices): These represent entities or objects.
Examples: A “Person,” “Product,” or “City.”
Analogy: Equivalent to a row in a relational database.
🔗 Edges (Relationships): These are the lines that connect nodes.
Function: They define how entities are related (e.g., “Follows,” “Bought,” or “Lives In”).
Details: Edges always have a start node, an end node, and a direction.
🏷️ Properties: These are key-value pairs used to store information about nodes or edges.
Example: A “Person” node might have name: "Alice" and age: 30.
📱 Real-World Example: Social Media Network
Imagine building a network like LinkedIn or Facebook.
The Setup:
👤 User A: Alice (lives in New York)
👤 User B: Bob (lives in San Francisco)
👤 User C: Charlie (lives in New York)
🏢 Company: TechCorp
The Relationships (Edges):
Alice 🤝 IS_FRIENDS_WITH ➡️ Bob
Bob 🤝 IS_FRIENDS_WITH ➡️ Charlie
Alice 💼 WORKS_AT ➡️ TechCorp
The Query Logic:
To suggest Charlie as a friend to Alice, the engine starts at the Alice node, traverses the IS_FRIENDS_WITH edge to Bob, and follows Bob’s connections to find Charlie. Because these links are physically stored, this “traversal” is instantaneous—even with millions of users! ⚡
⚖️ Relational (SQL) vs. Graph Database
Feature
🧱 Relational (SQL)
🕸️ Graph Database
Data Model
Rigid tables and schemas.
Flexible, evolving network.
Relationships
Calculated via JOINs at runtime.
Pre-stored and ready to traverse.
Best For
Transactional data (Accounting).
Connected data (AI, Social).
Performance
Slows down as links increase.
High speed regardless of depth.
🚀 Common Use Cases
🔍 Fraud Detection: Identifying complex patterns where different “customers” share the same phone number or IP address.
🛍️ Recommendation Engines: Suggesting products based on the “web” of what similar users bought.
🧠 Knowledge Graphs: Mapping intricate information, like Google’s search results or Wikipedia connections.
🕸️ Graph Database (గ్రాఫ్ డేటాబేస్)
Graph Database అనేది ఒక రకమైన NoSQL database. ఇది డేటాను రిప్రజెంట్ చేయడానికి మరియు స్టోర్ చేయడానికి graph structures (nodes, edges, మరియు properties) ఉపయోగిస్తుంది. మామూలు relational databases (tables, rows, columns) లాగా కాకుండా, ఇక్కడ data points మధ్య ఉండే relationships కి ఎక్కువ ఇంపార్టెన్స్ ఉంటుంది.
💡 ముఖ్యమైన విషయం: Graph database లో డేటా ఎంత ముఖ్యమో, వాటి మధ్య ఉండే connections కూడా అంతే ముఖ్యం.
🛠️ Key Components (ప్రధాన భాగాలు)
🔵 Nodes (Vertices): ఇవి entities లేదా objects ని సూచిస్తాయి.
ఉదాహరణకు: ఒక “Person,” “Product,” లేదా “City.” ఇవి relational database లోని ఒక row తో సమానం.
🔗 Edges (Relationships): ఇవి nodes ని కలిపే లైన్స్. రెండు entities మధ్య రిలేషన్ ఎలా ఉందో ఇవి చెప్తాయి.
ఉదాహరణకు: “Follows,” “Bought,” లేదా “Lives In.” ప్రతి edge కి ఒక start node, end node మరియు ఒక direction ఉంటాయి.
🏷️ Properties: ఇవి nodes లేదా edges కి సంబంధించిన అదనపు సమాచారాన్ని (metadata) స్టోర్ చేసే key-value pairs.
ఉదాహరణకు: ఒక “Person” node కి name: "Alice" మరియు age: 30 అనే properties ఉండవచ్చు.
📱 Real-World Example: Social Media Network
మీరు LinkedIn లేదా Facebook లాంటి ఒక social network బిల్డ్ చేస్తున్నారని ఊహించుకోండి. Relational database లో “friends of friends” ని వెతకాలంటే చాలా tables ని కలిపి కాంప్లెక్స్ JOIN operations చేయాలి, ఇది చాలా స్లోగా ఉంటుంది. కానీ Graph database లో కేవలం lines (edges) ని ఫాలో అయితే సరిపోతుంది.
📍 The Setup:
👤 Nodes: Alice, Bob, మరియు Charlie.
🤝 Edges:
Alice ➡️ IS_FRIENDS_WITH ➡️ Bob.
Bob ➡️ IS_FRIENDS_WITH ➡️ Charlie.
Alice ➡️ WORKS_AT ➡️ TechCorp.
⚡ The Query Logic:
Alice కి Charlie ని ఫ్రెండ్ గా సజెస్ట్ చేయాలంటే, database engine Alice node దగ్గర స్టార్ట్ అయ్యి, Bob కి ఉన్న IS_FRIENDS_WITH ఎడ్జ్ ద్వారా Charlie ని ఈజీగా వెతుకుతుంది. ఈ రిలేషన్స్ ఇప్పటికే database లో స్టోర్ అయి ఉండటం వల్ల, మిలియన్ల యూజర్లు ఉన్నా సరే ఈ traversal చాలా వేగంగా జరుగుతుంది.
⚖️ Why Use a Graph Database?
Feature
🧱 Relational (SQL)
🕸️ Graph Database
Data Model
Rigid tables మరియు schemas.
Flexible మరియు మారుతున్న network.
Relationships
Runtime లో JOINs ద్వారా లెక్కించాలి.
ముందే స్టోర్ అయి ఉంటాయి (Ready to traverse).
Best For
Transactional data (Accounting).
Connected data (Fraud detection, AI).
Performance
డేటా పెరిగేకొద్దీ స్లో అవుతుంది.
ఎంత లోతుగా వెళ్లినా High performance ఉంటుంది.
🚀 Common Use Cases (ఉపయోగాలు)
🔍 Fraud Detection: వేర్వేరు కస్టమర్లు ఒకే phone number లేదా IP address ని వాడుతున్నారా అనే patterns ని కనిపెట్టడానికి.
🛍️ Recommendation Engines: “మీలాంటి ఇంట్రెస్ట్ ఉన్న వాళ్లు ఈ ప్రొడక్ట్స్ కూడా కొన్నారు” అని సజెస్ట్ చేయడానికి.
🧠 Knowledge Graphs: Google search results లేదా Wikipedia లాంటి చోట్ల ఉండే సంక్లిష్టమైన సమాచారాన్ని ఒకదానితో ఒకటి లింక్ చేయడానికి.
🧠 Understanding MLOps MLOps (Machine Learning Operations) is a set of practices used to reliably and efficiently deploy and maintain machine learning models in production. 💡 To put it simply: If DevOps is the standard for building, testing, and releasing traditional software, MLOps is the equivalent for machine learning. 🚧 A common misconception: Many think…
🧑💻 What is Citizen Development? Citizen development is a business strategy where non-IT employees (often called “citizen developers”) create software applications or automate workflows to solve their own business problems. They do this using IT-approved low-code or no-code (LC/NC) platforms, meaning they don’t need to know how to write traditional programming code. ⏳ Instead of…
🎧 What is Spatial Audio? Spatial audio is a 3D audio technology designed to make sound feel like it is happening all around you, mimicking how you hear in real life. Instead of sound just being pumped directly into your left and right ears, spatial audio creates a virtual “soundscape” 🌐 where audio can come…
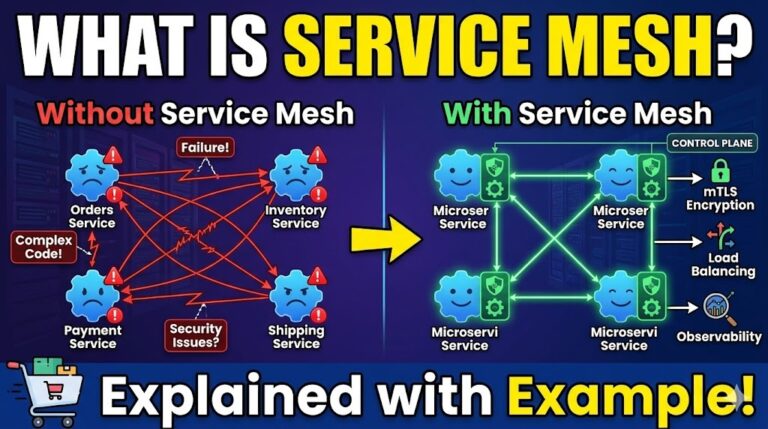
🌐 What is a Service Mesh? A service mesh is a dedicated infrastructure layer built right into an application that controls how different parts of that application (called microservices) share data with one another. 🏗️ In modern software, a single application might actually be made up of dozens or hundreds of independent, smaller services. As…
👆 What is Haptic Feedback?Haptic feedback is the use of touch to communicate with a user. Instead of relying only on sight 👁️ (displays) or sound 🔊 (alerts), a device uses physical forces, vibrations, or motions to give you a tactile response. Think of it as digital touch ✨. When you interact with a screen…
🧩 Micro-frontends are an architectural style where a single web application is split into smaller, independent, and manageable pieces. Think of it as taking the concept of microservices ⚙️ (which are used on the backend) and applying it to the frontend 🖥️. Instead of building one massive, monolithic frontend codebase that does everything, you build…